![]()
My Solutions#
Loading Packages#
from google.colab import auth
auth.authenticate_user()
print('Authenticated')
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/ipykernel/kernelbase.py in _input_request(self, prompt, ident, parent, password)
728 try:
--> 729 ident, reply = self.session.recv(self.stdin_socket, 0)
730 except Exception:
/usr/local/lib/python3.7/dist-packages/jupyter_client/session.py in recv(self, socket, mode, content, copy)
802 try:
--> 803 msg_list = socket.recv_multipart(mode, copy=copy)
804 except zmq.ZMQError as e:
/usr/local/lib/python3.7/dist-packages/zmq/sugar/socket.py in recv_multipart(self, flags, copy, track)
624 """
--> 625 parts = [self.recv(flags, copy=copy, track=track)]
626 # have first part already, only loop while more to receive
zmq/backend/cython/socket.pyx in zmq.backend.cython.socket.Socket.recv()
zmq/backend/cython/socket.pyx in zmq.backend.cython.socket.Socket.recv()
zmq/backend/cython/socket.pyx in zmq.backend.cython.socket._recv_copy()
/usr/local/lib/python3.7/dist-packages/zmq/backend/cython/checkrc.pxd in zmq.backend.cython.checkrc._check_rc()
KeyboardInterrupt:
During handling of the above exception, another exception occurred:
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-2-0aebb55fab46> in <module>()
2
3 from google.colab import auth
----> 4 auth.authenticate_user()
5 print('Authenticated')
6
/usr/local/lib/python3.7/dist-packages/google/colab/auth.py in authenticate_user(clear_output)
151 context_manager = _output.temporary if clear_output else _noop
152 with context_manager():
--> 153 _gcloud_login()
154 _install_adc()
155 colab_tpu_addr = _os.environ.get('COLAB_TPU_ADDR', '')
/usr/local/lib/python3.7/dist-packages/google/colab/auth.py in _gcloud_login()
93 # https://github.com/jupyter/notebook/issues/3159
94 prompt = prompt.rstrip()
---> 95 code = get_code(prompt + ' ')
96 gcloud_process.communicate(code.strip())
97 finally:
/usr/local/lib/python3.7/dist-packages/ipykernel/kernelbase.py in raw_input(self, prompt)
702 self._parent_ident,
703 self._parent_header,
--> 704 password=False,
705 )
706
/usr/local/lib/python3.7/dist-packages/ipykernel/kernelbase.py in _input_request(self, prompt, ident, parent, password)
732 except KeyboardInterrupt:
733 # re-raise KeyboardInterrupt, to truncate traceback
--> 734 raise KeyboardInterrupt
735 else:
736 break
KeyboardInterrupt:
import pandas as pa
import requests
from bs4 import BeautifulSoup
import re
import matplotlib.pyplot as plt
SQL Subquery#
%%bigquery --project pic-math
WITH t as (
SELECT COUNT(*) as number_trips, start_station_name
FROM `bigquery-public-data.austin_bikeshare.bikeshare_trips`
GROUP BY start_station_name
ORDER BY number_trips DESC
LIMIT 2
)
SELECT *
FROM t
ORDER BY number_trips
LIMIT 1
| number_trips | start_station_name | |
|---|---|---|
| 0 | 40635 | Riverside @ S. Lamar |
%%bigquery --project pic-math
SELECT COUNT(*) as round_trips, start_station_name
FROM `bigquery-public-data.austin_bikeshare.bikeshare_trips`
WHERE start_station_name = end_station_name AND duration_minutes >= 60
GROUP BY start_station_name
| round_trips | start_station_name | |
|---|---|---|
| 0 | 190 | Toomey Rd @ South Lamar |
| 1 | 119 | Waller & 6th St. |
| 2 | 249 | State Capitol @ 14th & Colorado |
| 3 | 83 | Rainey @ River St |
| 4 | 80 | Nueces @ 3rd |
| ... | ... | ... |
| 173 | 317 | Republic Square @ Guadalupe & 4th St. |
| 174 | 378 | 3rd & West |
| 175 | 169 | 3rd/West |
| 176 | 71 | 26th/Nueces |
| 177 | 86 | Nueces & 26th |
178 rows × 2 columns
SQL JOINS#
%%bigquery --project pic-math
WITH stations as (
SELECT name, property_type
FROM `bigquery-public-data.austin_bikeshare.bikeshare_stations`
)
SELECT stations.property_type as starting_station_type,
AVG(trips.duration_minutes) as average_ride_minutes,
count(*) as number_of_trips,
STDDEV_POP(trips.duration_minutes) as std_ride_minutes
FROM `bigquery-public-data.austin_bikeshare.bikeshare_trips` as trips
LEFT OUTER JOIN stations
ON trips.start_station_name = stations.name
WHERE stations.property_type = 'sidewalk' OR stations.property_type = 'parkland'
GROUP BY stations.property_type
ORDER BY average_ride_minutes DESC
##html Tables
html = requests.get('https://en.wikipedia.org/wiki/List_of_Marvel_Cinematic_Universe_films')
soup = BeautifulSoup(html.text)
df3 = pa.read_html(str(soup.find_all('table', class_='wikitable plainrowheaders')[0]))[0]
df3.columns = df3.columns.droplevel(1)
head = list(df3.columns[:-1])
head.append('Phase')
df3.columns = head
df3.Phase = [1,1,1,1,1,1,0,2,2,2,2,2,2,0,3,3,3,3,3,3,3,3,3,3,3]
df3.drop([6,13])
| Film | U.S. release date | Director(s) | Screenwriter(s) | Producer(s) | Phase | |
|---|---|---|---|---|---|---|
| 0 | Iron Man | May 2, 2008 | Jon Favreau[26] | Mark Fergus & Hawk Ostby and Art Marcum & Matt... | Avi Arad and Kevin Feige | 1 |
| 1 | The Incredible Hulk | June 13, 2008 | Louis Leterrier[28] | Zak Penn[29] | Avi Arad, Gale Anne Hurdand Kevin Feige | 1 |
| 2 | Iron Man 2 | May 7, 2010 | Jon Favreau[30] | Justin Theroux[31] | Kevin Feige | 1 |
| 3 | Thor | May 6, 2011 | Kenneth Branagh[32] | Ashley Edward Miller & Zack Stentz and Don Pay... | Kevin Feige | 1 |
| 4 | Captain America: The First Avenger | July 22, 2011 | Joe Johnston[34] | Christopher Markus & Stephen McFeely[35] | Kevin Feige | 1 |
| 5 | Marvel's The Avengers | May 4, 2012 | Joss Whedon[36] | Joss Whedon[36] | Kevin Feige | 1 |
| 7 | Iron Man 3 | May 3, 2013 | Shane Black[37] | Drew Pearce and Shane Black[37][38] | Kevin Feige | 2 |
| 8 | Thor: The Dark World | November 8, 2013 | Alan Taylor[39] | Christopher L. Yost and Christopher Markus & S... | Kevin Feige | 2 |
| 9 | Captain America: The Winter Soldier | April 4, 2014 | Anthony and Joe Russo[41] | Christopher Markus & Stephen McFeely[42] | Kevin Feige | 2 |
| 10 | Guardians of the Galaxy | August 1, 2014 | James Gunn[43] | James Gunn and Nicole Perlman[44] | Kevin Feige | 2 |
| 11 | Avengers: Age of Ultron | May 1, 2015 | Joss Whedon[45] | Joss Whedon[45] | Kevin Feige | 2 |
| 12 | Ant-Man | July 17, 2015 | Peyton Reed[46] | Edgar Wright & Joe Cornish and Adam McKay & Pa... | Kevin Feige | 2 |
| 14 | Captain America: Civil War | May 6, 2016 | Anthony and Joe Russo[48] | Christopher Markus & Stephen McFeely[48] | Kevin Feige | 3 |
| 15 | Doctor Strange | November 4, 2016 | Scott Derrickson[49] | Jon Spaihts and Scott Derrickson & C. Robert C... | Kevin Feige | 3 |
| 16 | Guardians of the Galaxy Vol. 2 | May 5, 2017 | James Gunn[44] | James Gunn[44] | Kevin Feige | 3 |
| 17 | Spider-Man: Homecoming | July 7, 2017 | Jon Watts[51] | Jonathan Goldstein & John Francis Daley andJon... | Kevin Feige and Amy Pascal | 3 |
| 18 | Thor: Ragnarok | November 3, 2017 | Taika Waititi[53] | Eric Pearson and Craig Kyle & Christopher L. Y... | Kevin Feige | 3 |
| 19 | Black Panther | February 16, 2018 | Ryan Coogler[56] | Ryan Coogler & Joe Robert Cole[57][58] | Kevin Feige | 3 |
| 20 | Avengers: Infinity War | April 27, 2018 | Anthony and Joe Russo[59] | Christopher Markus & Stephen McFeely[60] | Kevin Feige | 3 |
| 21 | Ant-Man and the Wasp | July 6, 2018 | Peyton Reed[61] | Chris McKenna & Erik Sommers andPaul Rudd & An... | Kevin Feige and Stephen Broussard | 3 |
| 22 | Captain Marvel | March 8, 2019 | Anna Boden and Ryan Fleck[63] | Anna Boden & Ryan Fleck & Geneva Robertson-Dwo... | Kevin Feige | 3 |
| 23 | Avengers: Endgame | April 26, 2019 | Anthony and Joe Russo[59] | Christopher Markus & Stephen McFeely[60] | Kevin Feige | 3 |
| 24 | Spider-Man: Far From Home | July 2, 2019 | Jon Watts[65] | Chris McKenna & Erik Sommers[66] | Kevin Feige and Amy Pascal | 3 |
html Selenium#
# RUN THIS CELL WHEN USING THE NOTEBOOK ON COLAB - NO PREVIOUS INSTALLATION OF SELENIUM IS NEEDED
# install chromium, its driver, and selenium
!apt update
!apt install chromium-chromedriver
!pip install selenium
# set options to be headless
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# open it, go to a website, and get results
driver = webdriver.Chrome('chromedriver',options=options)
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
0% [Working]
Get:1 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]
Get:2 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease [3,626 B]
Ign:3 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease
Hit:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease
Hit:5 http://archive.ubuntu.com/ubuntu bionic InRelease
Ign:6 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease
Get:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release [696 B]
Hit:8 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release
Get:9 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release.gpg [836 B]
Get:10 http://archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]
Hit:11 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease
Hit:12 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease
Get:13 http://archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]
Hit:14 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease
Get:15 http://security.ubuntu.com/ubuntu bionic-security/main amd64 Packages [2,544 kB]
Get:16 http://security.ubuntu.com/ubuntu bionic-security/restricted amd64 Packages [760 kB]
Get:17 http://security.ubuntu.com/ubuntu bionic-security/universe amd64 Packages [1,466 kB]
Get:19 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Packages [914 kB]
Get:20 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 Packages [2,986 kB]
Get:21 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages [2,244 kB]
Fetched 11.2 MB in 8s (1,484 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
51 packages can be upgraded. Run 'apt list --upgradable' to see them.
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
cuda-command-line-tools-10-0 cuda-command-line-tools-10-1
cuda-command-line-tools-11-0 cuda-compiler-10-0 cuda-compiler-10-1
cuda-compiler-11-0 cuda-cuobjdump-10-0 cuda-cuobjdump-10-1
cuda-cuobjdump-11-0 cuda-cupti-10-0 cuda-cupti-10-1 cuda-cupti-11-0
cuda-cupti-dev-11-0 cuda-documentation-10-0 cuda-documentation-10-1
cuda-documentation-11-0 cuda-documentation-11-1 cuda-gdb-10-0 cuda-gdb-10-1
cuda-gdb-11-0 cuda-gpu-library-advisor-10-0 cuda-gpu-library-advisor-10-1
cuda-libraries-10-0 cuda-libraries-10-1 cuda-libraries-11-0
cuda-memcheck-10-0 cuda-memcheck-10-1 cuda-memcheck-11-0 cuda-nsight-10-0
cuda-nsight-10-1 cuda-nsight-11-0 cuda-nsight-11-1 cuda-nsight-compute-10-0
cuda-nsight-compute-10-1 cuda-nsight-compute-11-0 cuda-nsight-compute-11-1
cuda-nsight-systems-10-1 cuda-nsight-systems-11-0 cuda-nsight-systems-11-1
cuda-nvcc-10-0 cuda-nvcc-10-1 cuda-nvcc-11-0 cuda-nvdisasm-10-0
cuda-nvdisasm-10-1 cuda-nvdisasm-11-0 cuda-nvml-dev-10-0 cuda-nvml-dev-10-1
cuda-nvml-dev-11-0 cuda-nvprof-10-0 cuda-nvprof-10-1 cuda-nvprof-11-0
cuda-nvprune-10-0 cuda-nvprune-10-1 cuda-nvprune-11-0 cuda-nvtx-10-0
cuda-nvtx-10-1 cuda-nvtx-11-0 cuda-nvvp-10-0 cuda-nvvp-10-1 cuda-nvvp-11-0
cuda-nvvp-11-1 cuda-samples-10-0 cuda-samples-10-1 cuda-samples-11-0
cuda-samples-11-1 cuda-sanitizer-11-0 cuda-sanitizer-api-10-1
cuda-toolkit-10-0 cuda-toolkit-10-1 cuda-toolkit-11-0 cuda-toolkit-11-1
cuda-tools-10-0 cuda-tools-10-1 cuda-tools-11-0 cuda-tools-11-1
cuda-visual-tools-10-0 cuda-visual-tools-10-1 cuda-visual-tools-11-0
cuda-visual-tools-11-1 default-jre dkms freeglut3 freeglut3-dev
keyboard-configuration libargon2-0 libcap2 libcryptsetup12
libdevmapper1.02.1 libfontenc1 libidn11 libip4tc0 libjansson4
libnvidia-cfg1-510 libnvidia-common-460 libnvidia-common-510
libnvidia-extra-510 libnvidia-fbc1-510 libnvidia-gl-510 libpam-systemd
libpolkit-agent-1-0 libpolkit-backend-1-0 libpolkit-gobject-1-0 libxfont2
libxi-dev libxkbfile1 libxmu-dev libxmu-headers libxnvctrl0
nsight-compute-2020.2.1 nsight-compute-2022.1.0 nsight-systems-2020.3.2
nsight-systems-2020.3.4 nsight-systems-2021.5.2 nvidia-dkms-510
nvidia-kernel-common-510 nvidia-kernel-source-510 nvidia-modprobe
nvidia-settings openjdk-11-jre policykit-1 policykit-1-gnome python3-xkit
screen-resolution-extra systemd systemd-sysv udev x11-xkb-utils
xserver-common xserver-xorg-core-hwe-18.04 xserver-xorg-video-nvidia-510
Use 'apt autoremove' to remove them.
The following additional packages will be installed:
chromium-browser chromium-browser-l10n chromium-codecs-ffmpeg-extra
Suggested packages:
webaccounts-chromium-extension unity-chromium-extension
The following NEW packages will be installed:
chromium-browser chromium-browser-l10n chromium-chromedriver
chromium-codecs-ffmpeg-extra
0 upgraded, 4 newly installed, 0 to remove and 51 not upgraded.
Need to get 95.3 MB of archives.
After this operation, 327 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-codecs-ffmpeg-extra amd64 97.0.4692.71-0ubuntu0.18.04.1 [1,142 kB]
Get:2 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-browser amd64 97.0.4692.71-0ubuntu0.18.04.1 [84.7 MB]
Get:3 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-browser-l10n all 97.0.4692.71-0ubuntu0.18.04.1 [4,370 kB]
Get:4 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-chromedriver amd64 97.0.4692.71-0ubuntu0.18.04.1 [5,055 kB]
Fetched 95.3 MB in 5s (19.9 MB/s)
Selecting previously unselected package chromium-codecs-ffmpeg-extra.
(Reading database ... 155113 files and directories currently installed.)
Preparing to unpack .../chromium-codecs-ffmpeg-extra_97.0.4692.71-0ubuntu0.18.04.1_amd64.deb ...
Unpacking chromium-codecs-ffmpeg-extra (97.0.4692.71-0ubuntu0.18.04.1) ...
Selecting previously unselected package chromium-browser.
Preparing to unpack .../chromium-browser_97.0.4692.71-0ubuntu0.18.04.1_amd64.deb ...
Unpacking chromium-browser (97.0.4692.71-0ubuntu0.18.04.1) ...
Selecting previously unselected package chromium-browser-l10n.
Preparing to unpack .../chromium-browser-l10n_97.0.4692.71-0ubuntu0.18.04.1_all.deb ...
Unpacking chromium-browser-l10n (97.0.4692.71-0ubuntu0.18.04.1) ...
Selecting previously unselected package chromium-chromedriver.
Preparing to unpack .../chromium-chromedriver_97.0.4692.71-0ubuntu0.18.04.1_amd64.deb ...
Unpacking chromium-chromedriver (97.0.4692.71-0ubuntu0.18.04.1) ...
Setting up chromium-codecs-ffmpeg-extra (97.0.4692.71-0ubuntu0.18.04.1) ...
Setting up chromium-browser (97.0.4692.71-0ubuntu0.18.04.1) ...
update-alternatives: using /usr/bin/chromium-browser to provide /usr/bin/x-www-browser (x-www-browser) in auto mode
update-alternatives: using /usr/bin/chromium-browser to provide /usr/bin/gnome-www-browser (gnome-www-browser) in auto mode
Setting up chromium-chromedriver (97.0.4692.71-0ubuntu0.18.04.1) ...
Setting up chromium-browser-l10n (97.0.4692.71-0ubuntu0.18.04.1) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Processing triggers for hicolor-icon-theme (0.17-2) ...
Processing triggers for mime-support (3.60ubuntu1) ...
Processing triggers for libc-bin (2.27-3ubuntu1.3) ...
/sbin/ldconfig.real: /usr/local/lib/python3.7/dist-packages/ideep4py/lib/libmkldnn.so.0 is not a symbolic link
Collecting selenium
Downloading selenium-4.1.0-py3-none-any.whl (958 kB)
|████████████████████████████████| 958 kB 18.1 MB/s
?25hCollecting trio-websocket~=0.9
Downloading trio_websocket-0.9.2-py3-none-any.whl (16 kB)
Collecting urllib3[secure]~=1.26
Downloading urllib3-1.26.8-py2.py3-none-any.whl (138 kB)
|████████████████████████████████| 138 kB 51.3 MB/s
?25hCollecting trio~=0.17
Downloading trio-0.19.0-py3-none-any.whl (356 kB)
|████████████████████████████████| 356 kB 44.2 MB/s
?25hRequirement already satisfied: attrs>=19.2.0 in /usr/local/lib/python3.7/dist-packages (from trio~=0.17->selenium) (21.4.0)
Collecting outcome
Downloading outcome-1.1.0-py2.py3-none-any.whl (9.7 kB)
Collecting async-generator>=1.9
Downloading async_generator-1.10-py3-none-any.whl (18 kB)
Requirement already satisfied: idna in /usr/local/lib/python3.7/dist-packages (from trio~=0.17->selenium) (2.10)
Collecting sniffio
Downloading sniffio-1.2.0-py3-none-any.whl (10 kB)
Requirement already satisfied: sortedcontainers in /usr/local/lib/python3.7/dist-packages (from trio~=0.17->selenium) (2.4.0)
Collecting wsproto>=0.14
Downloading wsproto-1.0.0-py3-none-any.whl (24 kB)
Requirement already satisfied: certifi in /usr/local/lib/python3.7/dist-packages (from urllib3[secure]~=1.26->selenium) (2021.10.8)
Collecting cryptography>=1.3.4
Downloading cryptography-36.0.1-cp36-abi3-manylinux_2_24_x86_64.whl (3.6 MB)
|████████████████████████████████| 3.6 MB 50.1 MB/s
?25hCollecting pyOpenSSL>=0.14
Downloading pyOpenSSL-22.0.0-py2.py3-none-any.whl (55 kB)
|████████████████████████████████| 55 kB 3.7 MB/s
?25hRequirement already satisfied: cffi>=1.12 in /usr/local/lib/python3.7/dist-packages (from cryptography>=1.3.4->urllib3[secure]~=1.26->selenium) (1.15.0)
Requirement already satisfied: pycparser in /usr/local/lib/python3.7/dist-packages (from cffi>=1.12->cryptography>=1.3.4->urllib3[secure]~=1.26->selenium) (2.21)
Collecting h11<1,>=0.9.0
Downloading h11-0.13.0-py3-none-any.whl (58 kB)
|████████████████████████████████| 58 kB 5.2 MB/s
?25hRequirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from h11<1,>=0.9.0->wsproto>=0.14->trio-websocket~=0.9->selenium) (3.10.0.2)
Installing collected packages: sniffio, outcome, h11, cryptography, async-generator, wsproto, urllib3, trio, pyOpenSSL, trio-websocket, selenium
Attempting uninstall: urllib3
Found existing installation: urllib3 1.24.3
Uninstalling urllib3-1.24.3:
Successfully uninstalled urllib3-1.24.3
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
requests 2.23.0 requires urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1, but you have urllib3 1.26.8 which is incompatible.
datascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.
Successfully installed async-generator-1.10 cryptography-36.0.1 h11-0.13.0 outcome-1.1.0 pyOpenSSL-22.0.0 selenium-4.1.0 sniffio-1.2.0 trio-0.19.0 trio-websocket-0.9.2 urllib3-1.26.8 wsproto-1.0.0
url = 'https://google.com'
driver.get(url)
elem = driver.find_element(By.XPATH, '//input')
elem.send_keys("Tottenham Football Club")
#elem = driver.find_element(By.XPATH, '//input[@name = "btnI"]')
elem.send_keys(Keys.ENTER)
driver.current_url
'https://www.google.com/search?q=Tottenham+Football+Club&source=hp&ei=QAT7YZXeJYDQytMPw8Ws4AI&iflsig=AHkkrS4AAAAAYfsSUMHkfn7vB6MqyKlrFkHY89DtlTuv&ved=0ahUKEwiV_outh-L1AhUAqHIEHcMiCywQ4dUDCAk&uact=5&oq=Tottenham+Football+Club&gs_lcp=Cgdnd3Mtd2l6EANQAFhjYIQBaABwAHgAgAEAiAEAkgEAmAEAoAEB&sclient=gws-wiz'
from bs4 import BeautifulSoup
soup = BeautifulSoup(driver.page_source)
soup.title
<title>Tottenham Football Club - Google Search</title>
The implicit wait did nothing for me. The best option seemed to be to do the staleness_of command. Waiting is hard!
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import staleness_of
old_page = driver.find_element(By.XPATH,'//html')
driver.find_element(By.PARTIAL_LINK_TEXT,'twitter').click()
WebDriverWait(driver, 10).until(staleness_of(old_page))
#driver.implicitly_wait(5)
driver.title
driver.current_url
'https://twitter.com/SpursOfficial?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor'
driver.title
'Tottenham Hotspur (@SpursOfficial) / Twitter'
driver.current_url
'https://twitter.com/SpursOfficial?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor'
Strings#
line = 'happy birthday to you\n'
print(line.capitalize() + line + line.replace("to you","dear {}".format(input("Enter the birthday celebrant's name: "))) + line)
Enter the birthday celebrant's name: Nick
Happy birthday to you
happy birthday to you
happy birthday dear Nick
happy birthday to you
String Cleaning#
import requests
import pandas as pa
from bs4 import BeautifulSoup
r = requests.get('https://en.wikipedia.org/wiki/List_of_highest_mountains_on_Earth')
html_contents = r.text
html_soup = BeautifulSoup(html_contents,"lxml")
tables = html_soup.find_all('table',class_="wikitable")
df1 = pa.read_html(str(tables))[0]
df1.columns = df1.columns.droplevel(0).droplevel(0)
df1.head()
cols = df1.columns.map(lambda s: re.sub(r"\[(.+)\]","",s))
cols
Index(['Rank', 'Mountain name(s)', 'm', 'ft', 'm', 'ft', 'Range',
'Coordinates', 'Parent mountain', '1st', 'y', 'n',
'Country (disputed claims in italics)'],
dtype='object')
re.sub(r"\((.+)\)","",cols[1])
'Mountain name'
cols = cols.map(lambda s: re.sub(r"\((.+)\)","",s))
cols
Index(['Rank', 'Mountain name', 'm', 'ft', 'm', 'ft', 'Range', 'Coordinates',
'Parent mountain', '1st', 'y', 'n', 'Country '],
dtype='object')
re.sub(r" ","_",cols[1])
'Mountain_name'
cols = cols.map(lambda s: s.strip())
cols
Index(['Rank', 'Mountain name', 'm', 'ft', 'm', 'ft', 'Range', 'Coordinates',
'Parent mountain', '1st', 'y', 'n', 'Country'],
dtype='object')
cols = cols.map(lambda s: re.sub(r" ","_",s))
cols
Index(['Rank', 'Mountain_name', 'm', 'ft', 'm', 'ft', 'Range', 'Coordinates',
'Parent_mountain', '1st', 'y', 'n', 'Country'],
dtype='object')
cols = cols.map(lambda s : s.lower())
cols
Index(['rank', 'mountain_name', 'm', 'ft', 'm', 'ft', 'range', 'coordinates',
'parent_mountain', '1st', 'y', 'n', 'country'],
dtype='object')
df1.columns = cols
df1.head()
| rank | mountain_name | m | ft | m | ft | range | coordinates | parent_mountain | 1st | y | n | country | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | .mw-parser-output ul.cslist,.mw-parser-output ... | 8848 | 29,029[dp 7] | 8848 | 29029 | Mahalangur Himalaya | .mw-parser-output .geo-default,.mw-parser-outp... | — | 1953 | 145 | 121 | NepalChina |
| 1 | 2 | K2 | 8611 | 28251 | 4020 | 13190 | Baltoro Karakoram | 35°52′53″N 76°30′48″E / 35.88139°N 76.51333°E | Mount Everest | 1954 | 45 | 44 | Pakistan[dp 8]China[12] |
| 2 | 3 | Kangchenjunga | 8586 | 28169 | 3922 | 12867 | Kangchenjunga Himalaya | 27°42′12″N 88°08′51″E / 27.70333°N 88.14750°E * | Mount Everest | 1955 | 38 | 24 | NepalIndia |
| 3 | 4 | Lhotse | 8516 | 27940 | 610 | 2000 | Mahalangur Himalaya | 27°57′42″N 86°55′59″E / 27.96167°N 86.93306°E | Mount Everest | 1956 | 26 | 26 | NepalChina |
| 4 | 5 | Makalu | 8485 | 27838 | 2378 | 7802 | Mahalangur Himalaya | 27°53′23″N 87°05′20″E / 27.88972°N 87.08889°E | Mount Everest | 1955 | 45 | — | NepalChina |
Strings and Regular Expressions Country Column Clean#
r = requests.get('https://en.wikipedia.org/wiki/List_of_highest_mountains_on_Earth')
html_contents = r.text
html_soup = BeautifulSoup(html_contents,"lxml")
tables = html_soup.find_all('table',class_="wikitable")
df1 = pa.read_html(str(tables))[0]
df1.columns = df1.columns.droplevel(0).droplevel(0)
df1.head()
df1.iloc[:,-1]
0 NepalChina
1 Pakistan[dp 8]China[12]
2 NepalIndia
3 NepalChina
4 NepalChina
...
115 China
116 NepalChina
117 BhutanChina[dp 18]
118 IndiaChina[dp 10][dp 11]'[dp 12]
119 Pakistan[dp 8]
Name: Country (disputed claims in italics), Length: 120, dtype: object
newcol = df1.iloc[:,-1]
newcol = newcol.apply(lambda x: re.sub(r"\[(.+?)\]","",x))
newcol
0 NepalChina
1 PakistanChina
2 NepalIndia
3 NepalChina
4 NepalChina
...
115 China
116 NepalChina
117 BhutanChina
118 IndiaChina'
119 Pakistan
Name: Country (disputed claims in italics), Length: 120, dtype: object
I still see an unexpected character, I’ll remove that one too.
newcol = newcol.apply(lambda x: re.sub(r"[^A-z]","",x))
newcol
0 NepalChina
1 PakistanChina
2 NepalIndia
3 NepalChina
4 NepalChina
...
115 China
116 NepalChina
117 BhutanChina
118 IndiaChina
119 Pakistan
Name: Country (disputed claims in italics), Length: 120, dtype: object
newcol = newcol.apply(lambda x: re.findall(r"[A-Z][a-z]*",x))
newcol
0 [Nepal, China]
1 [Pakistan, China]
2 [Nepal, India]
3 [Nepal, China]
4 [Nepal, China]
...
115 [China]
116 [Nepal, China]
117 [Bhutan, China]
118 [India, China]
119 [Pakistan]
Name: Country (disputed claims in italics), Length: 120, dtype: object
I need to find the most number of countries meeting. I find the length of each and find the max of that.
max(newcol.apply(lambda x: len(x)))
3
I know there are 3 possible countries. I’ll make three columns with the possible answers
newcols = pa.DataFrame(newcol.to_list(), columns = ['country1','country2','country3'])
newcols
| country1 | country2 | country3 | |
|---|---|---|---|
| 0 | Nepal | China | None |
| 1 | Pakistan | China | None |
| 2 | Nepal | India | None |
| 3 | Nepal | China | None |
| 4 | Nepal | China | None |
| ... | ... | ... | ... |
| 115 | China | None | None |
| 116 | Nepal | China | None |
| 117 | Bhutan | China | None |
| 118 | India | China | None |
| 119 | Pakistan | None | None |
120 rows × 3 columns
I’ll add that back into the dataframe using concat on axis = 1
df1 = pa.concat([df1,newcols], axis = 1)
df1.head()
| Rank[dp 1] | Mountain name(s) | m | ft | m | ft | Range | Coordinates[dp 4] | Parent mountain[dp 5] | 1st | y | n | Country (disputed claims in italics) | country1 | country2 | country3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | .mw-parser-output ul.cslist,.mw-parser-output ... | 8848 | 29,029[dp 7] | 8848 | 29029 | Mahalangur Himalaya | .mw-parser-output .geo-default,.mw-parser-outp... | — | 1953 | 145 | 121 | NepalChina | Nepal | China | None |
| 1 | 2 | K2 | 8611 | 28251 | 4020 | 13190 | Baltoro Karakoram | 35°52′53″N 76°30′48″E / 35.88139°N 76.51333°E | Mount Everest | 1954 | 45 | 44 | Pakistan[dp 8]China[12] | Pakistan | China | None |
| 2 | 3 | Kangchenjunga | 8586 | 28169 | 3922 | 12867 | Kangchenjunga Himalaya | 27°42′12″N 88°08′51″E / 27.70333°N 88.14750°E * | Mount Everest | 1955 | 38 | 24 | NepalIndia | Nepal | India | None |
| 3 | 4 | Lhotse | 8516 | 27940 | 610 | 2000 | Mahalangur Himalaya | 27°57′42″N 86°55′59″E / 27.96167°N 86.93306°E | Mount Everest | 1956 | 26 | 26 | NepalChina | Nepal | China | None |
| 4 | 5 | Makalu | 8485 | 27838 | 2378 | 7802 | Mahalangur Himalaya | 27°53′23″N 87°05′20″E / 27.88972°N 87.08889°E | Mount Everest | 1955 | 45 | — | NepalChina | Nepal | China | None |
Dates My Solutions#
iot = pa.read_csv('https://raw.githubusercontent.com/nurfnick/Data_Viz/main/IOT-temp.csv')
iot.head()
| id | room_id/id | noted_date | temp | out/in | |
|---|---|---|---|---|---|
| 0 | __export__.temp_log_196134_bd201015 | Room Admin | 08-12-2018 09:30 | 29 | In |
| 1 | __export__.temp_log_196131_7bca51bc | Room Admin | 08-12-2018 09:30 | 29 | In |
| 2 | __export__.temp_log_196127_522915e3 | Room Admin | 08-12-2018 09:29 | 41 | Out |
| 3 | __export__.temp_log_196128_be0919cf | Room Admin | 08-12-2018 09:29 | 41 | Out |
| 4 | __export__.temp_log_196126_d30b72fb | Room Admin | 08-12-2018 09:29 | 31 | In |
iot.shape
(97606, 5)
iot.noted_date = pa.to_datetime(iot.noted_date,format = '%d-%m-%Y %H:%M')
iot.noted_date.max()
Timestamp('2018-12-08 09:30:00')
iot.noted_date.min()
Timestamp('2018-07-28 07:06:00')
(iot.noted_date.shift() - iot.noted_date).max()
Timedelta('11 days 13:38:00')
(iot.noted_date.shift() - iot.noted_date).idxmax()
14038
That is a bigger jump than expected! The device must have been turned off or stopped outputting for a bit. Let’s see where that happened.
iot.iloc[14030:14050,:]
| id | room_id/id | noted_date | temp | out/in | |
|---|---|---|---|---|---|
| 14030 | __export__.temp_log_102425_e0206705 | Room Admin | 2018-11-17 10:35:00 | 46 | Out |
| 14031 | __export__.temp_log_142054_05d7f31e | Room Admin | 2018-11-17 10:31:00 | 45 | Out |
| 14032 | __export__.temp_log_132828_a446ef24 | Room Admin | 2018-11-17 10:29:00 | 44 | Out |
| 14033 | __export__.temp_log_130368_429948b8 | Room Admin | 2018-11-17 10:19:00 | 45 | Out |
| 14034 | __export__.temp_log_129679_c7815c3a | Room Admin | 2018-11-17 10:17:00 | 46 | Out |
| 14035 | __export__.temp_log_115558_f8f70efd | Room Admin | 2018-11-17 10:09:00 | 45 | Out |
| 14036 | __export__.temp_log_134401_87b1348c | Room Admin | 2018-11-17 09:43:00 | 46 | Out |
| 14037 | __export__.temp_log_134969_a8fe035c | Room Admin | 2018-11-17 09:41:00 | 45 | Out |
| 14038 | __export__.temp_log_105931_d412d864 | Room Admin | 2018-11-05 20:03:00 | 41 | Out |
| 14039 | __export__.temp_log_137841_5842365f | Room Admin | 2018-11-05 20:01:00 | 41 | Out |
| 14040 | __export__.temp_log_116451_f584e59d | Room Admin | 2018-11-05 19:59:00 | 40 | Out |
| 14041 | __export__.temp_log_90838_35fed2fd | Room Admin | 2018-11-05 19:57:00 | 41 | Out |
| 14042 | __export__.temp_log_100510_81c084b2 | Room Admin | 2018-11-05 19:56:00 | 32 | In |
| 14043 | __export__.temp_log_147095_21d94fe0 | Room Admin | 2018-11-05 19:53:00 | 41 | Out |
| 14044 | __export__.temp_log_110222_030f5157 | Room Admin | 2018-11-05 19:51:00 | 41 | Out |
| 14045 | __export__.temp_log_148651_5199c024 | Room Admin | 2018-11-05 19:47:00 | 42 | Out |
| 14046 | __export__.temp_log_108041_1583682c | Room Admin | 2018-11-05 19:44:00 | 32 | In |
| 14047 | __export__.temp_log_108105_9c42994b | Room Admin | 2018-11-05 19:43:00 | 41 | Out |
| 14048 | __export__.temp_log_129004_bf8c5c0c | Room Admin | 2018-11-05 19:41:00 | 41 | Out |
| 14049 | __export__.temp_log_111575_de593acd | Room Admin | 2018-11-05 19:39:00 | 41 | Out |
iot.noted_date.mean()
Timestamp('2018-10-07 05:10:38.821178880')
iot[iot.noted_date.dt.date == pa.Timestamp('09-11-2018')]
/usr/local/lib/python3.7/dist-packages/pandas/core/ops/array_ops.py:73: FutureWarning: Comparison of Timestamp with datetime.date is deprecated in order to match the standard library behavior. In a future version these will be considered non-comparable.Use 'ts == pd.Timestamp(date)' or 'ts.date() == date' instead.
result = libops.scalar_compare(x.ravel(), y, op)
| id | room_id/id | noted_date | temp | out/in | |
|---|---|---|---|---|---|
| 63867 | __export__.temp_log_13951_c7fd4bf2 | Room Admin | 2018-09-11 23:59:00 | 28 | Out |
| 63868 | __export__.temp_log_125783_87502329 | Room Admin | 2018-09-11 23:59:00 | 28 | In |
| 63869 | __export__.temp_log_117810_921a0b1d | Room Admin | 2018-09-11 23:59:00 | 27 | In |
| 63870 | __export__.temp_log_13950_419fb8ec | Room Admin | 2018-09-11 23:59:00 | 27 | Out |
| 63871 | __export__.temp_log_13945_96e421ea | Room Admin | 2018-09-11 23:58:00 | 27 | Out |
| ... | ... | ... | ... | ... | ... |
| 73364 | __export__.temp_log_118244_25e68d24 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
| 73365 | __export__.temp_log_135028_912344cf | Room Admin | 2018-09-11 07:38:00 | 33 | In |
| 73366 | __export__.temp_log_141419_d999d57a | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73367 | __export__.temp_log_112252_eee53ad5 | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73368 | __export__.temp_log_91587_c5eb7913 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
9502 rows × 5 columns
start = pa.Timestamp('09-11-2018')
end = pa.Timestamp('09-12-2018')
iot[iot.noted_date.between(start,end)]
| id | room_id/id | noted_date | temp | out/in | |
|---|---|---|---|---|---|
| 63853 | __export__.temp_log_113659_fad18b77 | Room Admin | 2018-09-12 00:00:00 | 27 | Out |
| 63854 | __export__.temp_log_13965_2d758a5b | Room Admin | 2018-09-12 00:00:00 | 27 | Out |
| 63855 | __export__.temp_log_148141_1ed4c048 | Room Admin | 2018-09-12 00:00:00 | 27 | Out |
| 63856 | __export__.temp_log_13964_b6650f58 | Room Admin | 2018-09-12 00:00:00 | 27 | Out |
| 63857 | __export__.temp_log_112729_9ad42af4 | Room Admin | 2018-09-12 00:00:00 | 27 | Out |
| ... | ... | ... | ... | ... | ... |
| 73364 | __export__.temp_log_118244_25e68d24 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
| 73365 | __export__.temp_log_135028_912344cf | Room Admin | 2018-09-11 07:38:00 | 33 | In |
| 73366 | __export__.temp_log_141419_d999d57a | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73367 | __export__.temp_log_112252_eee53ad5 | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73368 | __export__.temp_log_91587_c5eb7913 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
9516 rows × 5 columns
I tried for awhile to get around the deprecation warning and this was the best I could come up with. It does give me the first few readings that happen exactly at midnight. I am okay with that…
iot[(iot.noted_date.between(start,end))& (iot['out/in'] == 'Out')].temp.mean()
30.051679232350924
Actually I can fix that by not allowing the the inclusion of the right endpoint.
iot[iot.noted_date.between(start,end, inclusive = 'left')]
| id | room_id/id | noted_date | temp | out/in | |
|---|---|---|---|---|---|
| 63867 | __export__.temp_log_13951_c7fd4bf2 | Room Admin | 2018-09-11 23:59:00 | 28 | Out |
| 63868 | __export__.temp_log_125783_87502329 | Room Admin | 2018-09-11 23:59:00 | 28 | In |
| 63869 | __export__.temp_log_117810_921a0b1d | Room Admin | 2018-09-11 23:59:00 | 27 | In |
| 63870 | __export__.temp_log_13950_419fb8ec | Room Admin | 2018-09-11 23:59:00 | 27 | Out |
| 63871 | __export__.temp_log_13945_96e421ea | Room Admin | 2018-09-11 23:58:00 | 27 | Out |
| ... | ... | ... | ... | ... | ... |
| 73364 | __export__.temp_log_118244_25e68d24 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
| 73365 | __export__.temp_log_135028_912344cf | Room Admin | 2018-09-11 07:38:00 | 33 | In |
| 73366 | __export__.temp_log_141419_d999d57a | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73367 | __export__.temp_log_112252_eee53ad5 | Room Admin | 2018-09-11 07:38:00 | 32 | Out |
| 73368 | __export__.temp_log_91587_c5eb7913 | Room Admin | 2018-09-11 07:38:00 | 33 | Out |
9502 rows × 5 columns
iot[(iot.noted_date.between(start,end, inclusive = "left"))& (iot['out/in'] == 'Out')].temp.mean()
30.057547040241726
I was right not to worry about that shifting the average too much…
Integers and Floats#
df = pa.read_csv('https://raw.githubusercontent.com/nurfnick/Data_Viz/main/iris.csv')
df.head()
| SepalLength | SepalWidth | PedalLength | PedalWidth | Class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
df.SepalLength.mean()
5.843333333333335
df.SepalLength.astype('int').mean()
5.386666666666667
df.groupby('Class').agg('mean')
| SepalLength | SepalWidth | PedalLength | PedalWidth | |
|---|---|---|---|---|
| Class | ||||
| Iris-setosa | 5.006 | 3.418 | 1.464 | 0.244 |
| Iris-versicolor | 5.936 | 2.770 | 4.260 | 1.326 |
| Iris-virginica | 6.588 | 2.974 | 5.552 | 2.026 |
Cannot just convert a groupby!
df.groupby('Class').astype('int').agg('mean')
df2 = df[['PedalLength','PedalWidth','SepalLength','SepalWidth']].astype('int')
df2 = pa.concat([df2,df.Class],axis = 1)
df2.head()
| PedalLength | PedalWidth | SepalLength | SepalWidth | Class | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 5 | 3 | Iris-setosa |
| 1 | 1 | 0 | 4 | 3 | Iris-setosa |
| 2 | 1 | 0 | 4 | 3 | Iris-setosa |
| 3 | 1 | 0 | 4 | 3 | Iris-setosa |
| 4 | 1 | 0 | 5 | 3 | Iris-setosa |
df2.groupby('Class').agg('mean')
| PedalLength | PedalWidth | SepalLength | SepalWidth | |
|---|---|---|---|---|
| Class | ||||
| Iris-setosa | 1.00 | 0.00 | 4.60 | 3.04 |
| Iris-versicolor | 3.82 | 1.00 | 5.48 | 2.32 |
| Iris-virginica | 5.10 | 1.58 | 6.08 | 2.58 |
df.groupby('Class').agg(['mean','median','count','std'])
| SepalLength | SepalWidth | PedalLength | PedalWidth | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | median | count | std | mean | median | count | std | mean | median | count | std | mean | median | count | std | |
| Class | ||||||||||||||||
| Iris-setosa | 5.006 | 5.0 | 50 | 0.352490 | 3.418 | 3.4 | 50 | 0.381024 | 1.464 | 1.50 | 50 | 0.173511 | 0.244 | 0.2 | 50 | 0.107210 |
| Iris-versicolor | 5.936 | 5.9 | 50 | 0.516171 | 2.770 | 2.8 | 50 | 0.313798 | 4.260 | 4.35 | 50 | 0.469911 | 1.326 | 1.3 | 50 | 0.197753 |
| Iris-virginica | 6.588 | 6.5 | 50 | 0.635880 | 2.974 | 3.0 | 50 | 0.322497 | 5.552 | 5.55 | 50 | 0.551895 | 2.026 | 2.0 | 50 | 0.274650 |
Visualize Amounts#
import pandas as pa
df3 = pa.read_csv('https://raw.githubusercontent.com/nurfnick/Data_Viz/main/AB_NYC_2019.csv')
!pip install --upgrade matplotlib
Requirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (3.2.2)
Collecting matplotlib
Downloading matplotlib-3.5.1-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (11.2 MB)
|████████████████████████████████| 11.2 MB 27.8 MB/s
?25hRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (1.4.0)
Collecting fonttools>=4.22.0
Downloading fonttools-4.31.2-py3-none-any.whl (899 kB)
|████████████████████████████████| 899 kB 46.1 MB/s
?25hRequirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (7.1.2)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (2.8.2)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (1.21.5)
Requirement already satisfied: pyparsing>=2.2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (3.0.7)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (21.3)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (0.11.0)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from kiwisolver>=1.0.1->matplotlib) (3.10.0.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7->matplotlib) (1.15.0)
Installing collected packages: fonttools, matplotlib
Attempting uninstall: matplotlib
Found existing installation: matplotlib 3.2.2
Uninstalling matplotlib-3.2.2:
Successfully uninstalled matplotlib-3.2.2
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
albumentations 0.1.12 requires imgaug<0.2.7,>=0.2.5, but you have imgaug 0.2.9 which is incompatible.
Successfully installed fonttools-4.31.2 matplotlib-3.5.1
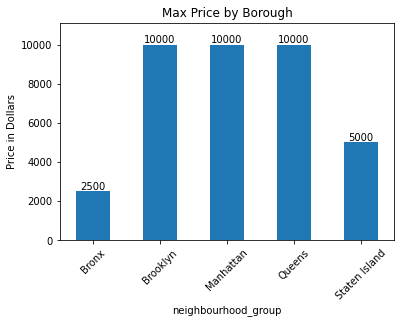
ax = df3.groupby('neighbourhood_group').price.agg('max').plot.bar(ylim = [0,11100],
title = 'Max Price by Borough',
ylabel = 'Price in Dollars',
rot = 45)
for container in ax.containers:
ax.bar_label(container)
df3.groupby(['neighbourhood_group','room_type']).price.agg('max').plot.bar(y = 'room_type')
<matplotlib.axes._subplots.AxesSubplot at 0x7f0f5b778e90>
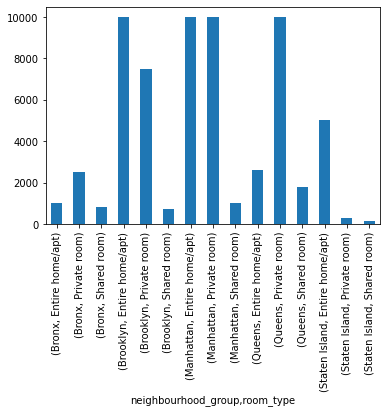
I had to do it with a pivot table to get around the double indexing of the groupby.
df_pivot = pa.pivot_table(
df3,
values="price",
index="neighbourhood_group",
columns="room_type",
aggfunc=max
)
df_pivot.plot.bar(title = 'Grouped by Borough')
<matplotlib.axes._subplots.AxesSubplot at 0x7f0f5b7ec410>
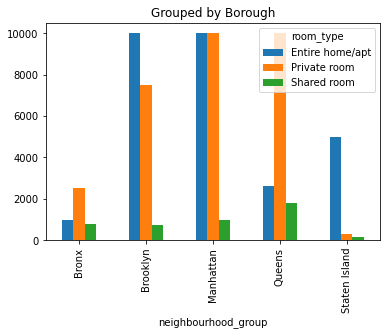
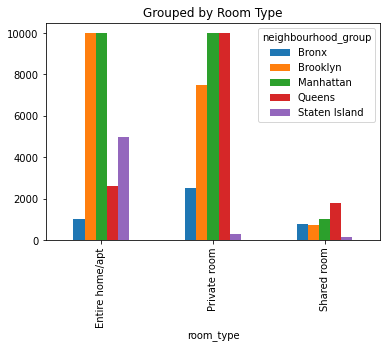
df_pivot
| room_type | Entire home/apt | Private room | Shared room |
|---|---|---|---|
| neighbourhood_group | |||
| Bronx | 1000 | 2500 | 800 |
| Brooklyn | 10000 | 7500 | 725 |
| Manhattan | 10000 | 9999 | 1000 |
| Queens | 2600 | 10000 | 1800 |
| Staten Island | 5000 | 300 | 150 |
df_pivot = pa.pivot_table(
df3,
values="price",
index="room_type",
columns="neighbourhood_group",
aggfunc=max
)
df_pivot.plot.bar(title = 'Grouped by Room Type')
<matplotlib.axes._subplots.AxesSubplot at 0x7f0f5b12f310>
Visualize Histograms#
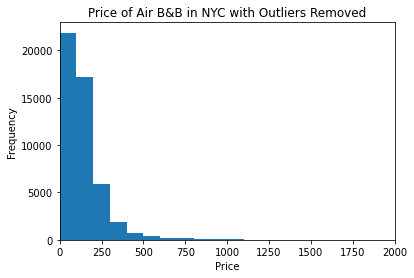
df3.price.plot.hist(title = "Price of Air B&B in NYC with Outliers Removed",bins = 100, xlim = [0,2000]).set_xlabel("Price")
Text(0.5, 0, 'Price')
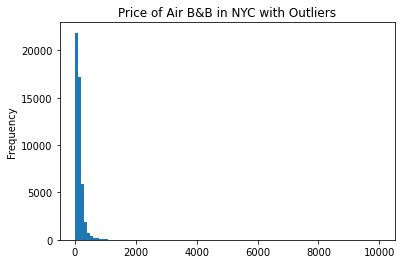
df3.price.plot.hist(title = "Price of Air B&B in NYC with Outliers",bins = 100)
<matplotlib.axes._subplots.AxesSubplot at 0x7f0f557fb210>
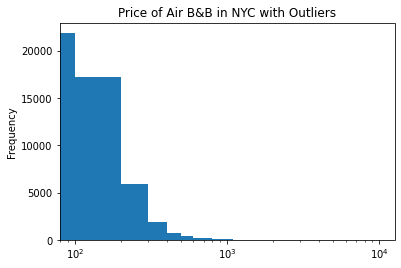
df3.price.plot.hist(title = "Price of Air B&B in NYC with Outliers",bins = 100, logx = True)
<matplotlib.axes._subplots.AxesSubplot at 0x7f865ca97150>
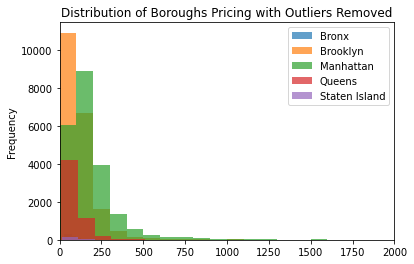
df3.groupby('neighbourhood_group').price.plot.hist(alpha = .7, bins = 100, xlim = [0,2000], legend = True, title = "Distribution of Boroughs Pricing with Outliers Removed")
neighbourhood_group
Bronx AxesSubplot(0.125,0.125;0.775x0.755)
Brooklyn AxesSubplot(0.125,0.125;0.775x0.755)
Manhattan AxesSubplot(0.125,0.125;0.775x0.755)
Queens AxesSubplot(0.125,0.125;0.775x0.755)
Staten Island AxesSubplot(0.125,0.125;0.775x0.755)
Name: price, dtype: object
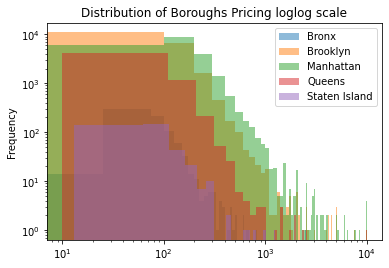
df3.groupby('neighbourhood_group').price.plot.hist(alpha = .5, bins = 100, legend = True, title = "Distribution of Boroughs Pricing loglog Scale", logx = True, logy = True)
plt.show()
Visualize Proportions#
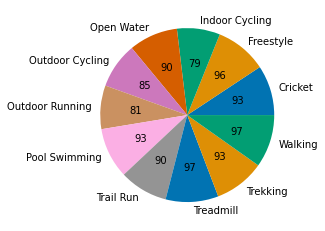
I’ll limit the number of colors passed to it to be just 7 instead of 10. The percent will have to be converted back to a total. I do that with a function. I also do this in two ways.
import pandas as pa
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df = pa.read_csv('https://raw.githubusercontent.com/nurfnick/Data_Viz/main/Activity_Dataset_V1.csv')
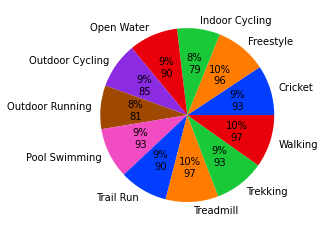
def func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:.0f}%\n{:d}".format(pct, absolute)
plt.pie(x=df.groupby('workout_type').workout_type.agg('count'),
labels = df.groupby('workout_type').workout_type.agg('count').index,
autopct=lambda pct: func(pct,df.groupby('workout_type').workout_type.agg('count')),
colors = sns.color_palette('bright')[:7])
plt.show()
If you just want the total;
def func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:d}".format(absolute)
plt.pie(x=df.groupby('workout_type').workout_type.agg('count'),
labels = df.groupby('workout_type').workout_type.agg('count').index,
autopct=lambda pct: func(pct,df.groupby('workout_type').workout_type.agg('count')),
colors = sns.color_palette('colorblind')[:8])
plt.show()